Appendix E. Internal File Data Formats
- Table of Contents
- E.1. ZMailer's Files and Formats
- E.2. Envelope Header Lines
- E.3. Message Control File
- E.4. Database File Formats
-
- E.4.1. The dbases.conf file
- E.4.2. Aliases File
- E.4.3. FQDNAliases File
- E.4.4. Routes File
- E.4.5. Localnames
- E.4.6. Otherservers
- E.4.7. Iproutes
- E.4.8. Fullnames
- E.4.9. Userdb
- E.4.10. Expiredaccts
- E.4.11. Active (newsgroups)
- E.4.12. Aliases.ldap
- E.4.13. Fqdnaliases.ldap
- E.4.14. Mailbox File
- E.5. Scheduler Statistics Log
- E.6. Syslogged Log Formats
-
- E.6.1. Smtpserver's Syslog Format
- E.6.2. Router's Syslog Format
- E.6.3. Transport Agent's Syslog Format
E.2. Envelope Header Lines
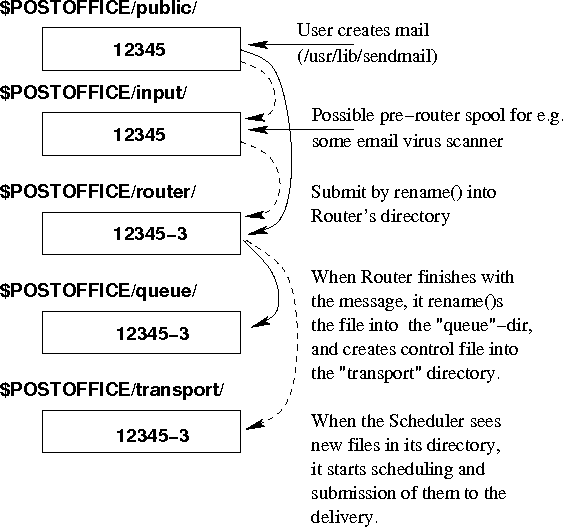
As the router picks up message files from a specific directory. Normally, message file names can be arbitrary valid file names, and indeed this is convenient when debugging. However, because the router daemon scans its own current directory, miscellaneous output from the router process may show up in this directory (e.g. profiling data, or core dumps (unthinkable as that is)). Furthermore, it is useful to be able to hide files from the router scanning (indeed the router may wish to do so itself).
When the process is scanning for message files, it only considers file names that have a certain format. Specifically, the message file name must start with a digit. This method was chosen to accomodate the message file names, as generated by the standard submission interface library routines, which will be strings of digits representing the message file's inode number.
A message file contains three sections: the message envelope, the message header, and the message body (in that order). he message body is separated from the previous sections by a blank line. The message body may be empty, and either of the message envelope or message header may be empty. The restriction on the latter situation, is that one of those sections must contain destination information for the message.
The message envelope and the message header have very similar syntax. The only difference is that while the message header must adhere to RFC822, the message envelope header fields are terminated by whitespace (“ ”) instead of a colon (“:”). The semantics of the two message file sections is quite different, and will be covered later.
The message envelope headers are used to carry meta-information about the message. The goal is to carry transport-envelope information separate from message (RFC-822) headers, and body. At first the message starts with a set of envelope headers (*-prefix denotes optional):
*external \n *rcvdfrom %s (%s) \n *bodytype %s \n *errormsg \n *with %s \n *identinfo %s \n Either: from <%s> \n Or: channel error \n *envid %s \n *notaryret %s \n Then for each recipient pairs of: *todsn [NOTIFY=...] [ORCPT=...] \n to <%s> \n Just before the data starts, a magic entry: env-end \n |
The header fields recognized by ZMailer in the message envelope are:
bodytypeword-
not used. Compatibility with the sendmail feature
channelword-
sets the channel corresponding to the message origin(*), usually as “channel error”
commentstring-
arbitrary comment
env-end-
separator flag-word in between the envelope and the RFC822 headers
env-eof-
alias to
env-end errormsg-
Special internal flag-word telling that the message in question has been produced by scheduler or errormail, and is considered an error message.
This distinction can be used at routing to determine use of different default route lookup key for recipients in this case. See file p-routes.cf.
envidxtext-
ESMTP DSN ENVID value
external-
A flag-word indicating the external origin of a message
from“address”-
a source address(*)
fullname“phrase”-
sets the full name of the local sender
identinfo“string”-
The SMTP server's ident lookup result, this does not guarantee anything about the sender though.
loginname“word”-
requests using this mail id for the local sender
notaryret“word”-
ESMTP DSN RET=word, either “FULL”, or “HDRS”
rcvdfrom“domain” (opt comment)-
An optional envelope entry, which sets “Received:” header's “from” field value.
This should only be used on messages that are originated thru “trusted” mechanisms, and especially not be used when the message is originated by some John Doe in the system. (E.g. this is reserved for smtpserver and friends, not for arbitrary users.)
to“address-list”-
Normal recipient address list; usually used in form of listing one address in angle braces:
to <user@somewhere>
todsn“phrase”-
ESMTP DSN recipient parameters. Note: this must be before the recipient “
to” line for which this gives the extra parameters. user“local-part”-
Optional envelope entry telling who the message originating user was. The system is extremely suspicuous on this entry, and will check it against system account database, unless the spool file owner uid is known to belong to trusted users.
verbose“filename”-
This optional envelope entry tells the router, what filename the sending client expects the subsystems to use as a feedback channel for reports concerning the file.
This “filename” is located into $
POSTOFFICE/public/ directory, and has been preopened by the same uid as has created the message spool file. via“word”-
An optional envelope entry that will define “Received:” header's optional “via” tag telling what physical transport mechanism was used.
Usually this entry is not used. (For an exceptions, see rmail and listexpand utility.)
with“word”-
An optional envelope entry that will define “Received:” header's optional “with” tag telling what protocol was used.
Unlike RFC-822 tells, ZMailer supports only one “with” instance.
The (*)'s beside the descriptions indicate this is a privileged field. That is, the action will only happen if ZMailer trusts the owner of the message file (*Note Security: security. XREF ??). As with a normal RFC822 header, other fields are allowed (though they will be ignored), and case is not significant in the field name. The router will do appropriate checks for the fields that require it.
With this knowledge, we can now appreciate the minimal message file:
==================== to bond ==================== |
This will cause an empty message to be sent to bond. A slightly more sophisticated version is:
====================
from m
to bond
via courier
env-end
From: M
To: Bond
Subject: do get a receipt, 007!
You are working for the Government, remember?
====================
|
Notice that there is no delimiter between the message envelope and the message header. A more sophisticated example in the same vein:
====================
from ps/d-ops
to <007@sis.mod.uk>
env-end
From: M <d-ops@sis.mod.uk>
Sender: Moneypenny <ps/d-ops@sis.mod.uk>
To: James Bond <007@sis.mod.uk>
Subject: where are you???!
Classification: Top Secret
Priority: Flash
We have another madman on the loose. Contact "Q" for usual routine.
====================
|
If the Classification: header is paid attention to in ZMailer, this requires that the router recognize it in the message header, and take appropriate action. In general the router can extract most of the information in the message header, and make use of it if the information is lacking in the envelope. The envelope headers in the above message are superfluous, since the same information is contained in the message header. Using the following envelope headers would be exactly equivalent to using the ones shown above (assuming the local host is sis.mod.uk):
==================== From Moneypenny <ps/d-ops@sis.mod.uk> To James Bond <007@sis.mod.uk> ... ==================== |
ZMailer will extract the appropriate address information from whatever the field values are, as long as they obey the defined syntax (indicated in the list of recognized envelope fields above). ZMailer will complain in case of unexpected errors in the envelope headers.
The message body is not interpreted by ZMailer itself. As far as the router is concerned, it can be arbitrary data. However, certain Transport Agents may require limitations on the message body data. For example, the SMTP only deals with ASCII data with a small guaranteed line length.
E.3. Message Control File
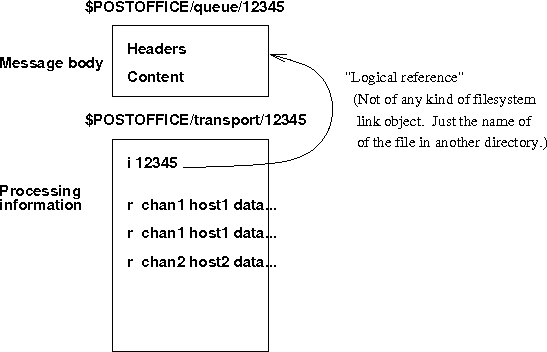
A message control file is a file created by the router to contain all the information necessary for delivery of a message submitted in a corresponding message file. It is interpreted by the scheduler, which needs to know at all times which messages are pending to go where, and how. It is also interpreted by one or more Transport Agents, possibly concurrently, that extract the delivery information relevant to their purpose.
The concurrency aspect means that the Transport Agents must cooperate on a locking protocol to ensure that delivery to a particular destination is attempted by only one Transport Agent at a time, and a status protocol to ensure unique success or failure of delivery for each destination. There are potentially many ways to implement such protocols, but, in the spirit of simplicity, ZMailer uses a control file as a form of shared memory. Specific locations within each control file are reserved for flags that indicate a specific state for their associated destination address. The rest is taken care of by the I/O semantics when multiple processes update the same file.
Apart from necessary envelope and control information, a control file also contains the new message header for the message, which contains the header addresses as rewritten by the router. Since a message may have several destinations with incompatible address format requirements, there may be several corresponding groups of message headers. This will be illustrated by the sample control file shown in the following subsection.
E.3.1. Format
A control file consists of a sequence of fields. Each field starts at the beginning of a line (i.e. at byte 0 or after a Newline), and is identified by the appearance of a specific character in that location. This id character is normally followed by a byte containing a tag value (semaphore flag), followed by the field value.
Here is a simple control file produced by a test message, just before it was removed by the Scheduler:
==================== @ 0x00000007 i 24700 o 72 l <88Jan10.003129est.24700@bay.csri.toronto.edu> e Rayan Zachariassen <rayan> s local - rayan r+ local - rayan 2003 m Received: by bay.csri.toronto.edu id 24700; Sun, 10 Jan 88 00:31:29 EST From: Rayan Zachariassen <rayan> To: rayan, rayan@ephemeral Subject: a test Message-Id: <88Jan10.003129est.24700@bay.csri.toronto.edu> Date: Sun, 10 Jan 88 00:31:24 EST s local - rayan@bay.csri.toronto.edu r+ smtp ephemeral.ai.toronto.edu rayan@ephemeral.ai.toronto.edu 2003 m Received: by bay.csri.toronto.edu id 24700; Sun, 10 Jan 88 00:31:29 EST From: Rayan Zachariassen <rayan@csri.toronto.edu> To: rayan@csri.toronto.edu, rayan@ephemeral.ai.toronto.edu Subject: a test Message-Id: <88Jan10.003129est.24700@bay.csri.toronto.edu> Date: Sun, 10 Jan 88 00:31:24 EST ==================== |
The id character values are defined in the mail.h system header file, which currently contains:
/* These are in order (roughly) what the router writes out. */
#define _CF_FORMAT '@' /* What format variant are we ?? */
#define _CF_FORMAT_TA_PID 0x00000001 /* At 'r' or 'X' lines */
#define _CF_FORMAT_DELAY1 0x00000002 /* At 'r' or 'X' lines */
#define _CF_FORMAT_MIMESTRUCT 0x00000004 /* The 'M' block */
#define _CF_FORMAT_KNOWN_SET (_CF_FORMAT_DELAY1|_CF_FORMAT_TA_PID | \
_CF_FORMAT_MIMESTRUCT)
#define _CF_VERBOSE 'v' /* log file name for verbose log (mail -v) */
#define _CF_MESSAGEID 'i' /* inode number of file containing message */
#define _CF_BODYOFFSET 'o' /* byte offset into message file of body */
#define _CF_LOGIDENT 'l' /* identification string for log entries */
#define _CF_BODYFILE 'b' /* alternate message file for new body */
#define _CF_ERRORADDR 'e' /* return address for error messages */
#define _CF_OBSOLETES 'x' /* message id of message obsoleted by this */
#define _CF_TURNME 'T' /* trigger scheduler to attempt delivery now */
#define _CF_SENDER 's' /* sender triple (channel, host, user) */
#define _CF_RECIPIENT 'r' /* recipient n-tuple, n >= 3 */
#define _CF_DSNRETMODE 'R' /* DSN message body return control */
#define _CF_XORECIPIENT 'X' /* one of XOR set of recipient n-tuples */
#define _CF_RCPTNOTARY 'N' /* DSN parameters for previous recipient */
#define _CF_DSNENVID 'n' /* DSN 'MAIL FROM<> ENVID=XXXX' data */
#define _CF_MSGHEADERS 'm' /* message header for preceeding recipients */
#define _CF_MIMESTRUCT 'M' /* compacted MIME structure data for message */
#define _CF_DIAGNOSTIC 'd' /* diagnostic message for ctlfile offset */
/* The following characters may appear in the second column after most _CF_* */
#define _CFTAG_NORMAL ' ' /* what the router sets it to be */
#define _CFTAG_LOCK '~' /* that line is being processed, lock it */
#define _CFTAG_OK '+' /* positive outcome of processing */
#define _CFTAG_NOTOK '-' /* something went wrong */
#define _CFTAG_DEFER _CFTAG_NORMAL /* try again later */
|
There is one field per line, except for _CF_MSGHEADERS, and _CF_MIMESTRUCT, which have some special semantics described below.
The following describes the fields in detail:
@hex-encoded-bitflagset-
This carries a hex-encoded bitflag set which is used by the scheduler, and Transport Agents to detect if the router produces files with incompatible features to what the latter programs know.
This is used to ensure that there stays a capability relation of:
router <= scheduler <= transport-agents
For example:
@ 0x00000007
vrelative-file-path-
Log file name for verbose log (mail -v):
v ../public/v_some_magic_tmpfile
ifilename-
This field identifies the message file corresponding to this control file. It is the name of the message file in the QUEUE directory ($
POSTOFFICE/queue/).This is typically the same as the inode number for that file, but need not be. It is used by Transport Agents when copying the message body, and by the scheduler when unlinking the file after all of the destination addresses have been processed.
For example:
i 21456-789
odecimal-number-
Specifies the byte offset of the message body in the message file. It is used by Transport Agents in order to copy the message body quickly, without parsing the message file.
For example:
o 466
lmessage-id-string-
The field value is an uninterpreted string which should prefix all log messages and accounting records associated with this message. This value is typically the message id string.
For example:
l <88Jan6.103158gmt.24694@sis.mod.uk>
bfilename-
Alternate message file for new body. (Currently not supported!)
eerror-address-
Gives an address to which delivery errors should be sent. The address must be a RFC822 mailbox.
For example:
e "Operations Directorate" <d-ops@sis.mod.uk>
xmessage-id-string-
Message id of message obsoleted by this.
T-
This is mainly smtpserver created message directing the scheduler to trigger sending of given queue (or other parameter) right (resources permitting). This is mainly superceded by MAILQv2 ETRN IPC mechanism.
For example:
T some.specific.domain (trigger originator IP address)
ssender-quad-
This field specifies an originator (sender) address triple, in the sequence: previous channel, previous host, return address. It remains the current sender address until the next instance of this field.
Since there can only be one sender of a message, multiple instances of the field will correspond to different return address formats as produced by the
crossbaralgorithm in the router.For example:
s smtp sis.mod.uk @lab.sis.mod.uk:q@deadly-sun.lab.sis.mod.uk s uucp sisops lab.sis.mod.uk!deadly-sun.lab.sis.mod.uk!q
r10-spaces rcpt-quad-
This field specifies a destination (recipient) address triple, in the sequence: next channel, next host, address for next host. Optional information to be passed to the Transport Agent may be placed after the mandatory fields; this currently refers to the delivery privilege of the destination address. Since the optional values of this field are only interpreted by the Transport Agent, changes in what the router writes must be coordinated with the code of the Transport Agents that might interpret this field.
For recipient processing interlocks, and delay report flags there is 6+4 spaces before the actual recipient address quad.
For example:
==123456ABCD.... r local - bond 0 r uucp uunet sisops!bond -2
X-
One of XOR set of recipient 4-tuples. (Not used so far.)
N-
DSN parameters for previous recipient.
For example:
==123456ABCD.... r local - bond 0 N ORCPT=rfc822;bond NOTIFY=DELAY,FAILURE
R-
DSN message body return control flag. (While this is stored once per every message
For example:
==123456ABCD.... r local - bond 0 N ORCPT=rfc822;bond NOTIFY=DELAY,FAILURE R HDRS
n-
DSN MAIL FROM<..> ENVID=XXXX data.
For example:
==123456ABCD.... r local - bond 0 N ORCPT=rfc822;bond NOTIFY=DELAY,FAILURE R HDRS n XXXX
m-
Apart from a message body, a Transport Agent needs the message headers to construct the message it delivers. These message headers are stored as the value of this field.
Since message headers obviously can span lines, the syntax for this field is somewhat different than for the others. The field id is immediately followed by a newline, which is followed by a complete set of message headers. These are terminated (in the usual fashion) by an empty line, which also terminates this field.
In the following example, the last line of text is followed by an empty line, after which another field may start:
m From: M To: Bond Subject: do get a receipt, 007! s ... r ...
M-
This is another multi-line structure reserved for latter support of pre-scanned MIME structure data so that the transport-agents have easier work ahead of them when planning things like content transformations during the transport action. (12-Mar-2001)
d-
This field is not written by the router. It is written by the scheduler or Transport Agents to remember errors associated with specific addresses. The field value has two parts, the first being the byte offset in the control file of the destination (recipient) address causing the error, and the rest of the line being an error message. The Transport Agents discover these errors and report them to the scheduler.
The scheduler will collect them and report them to the error return address (if any) after all the destinations have been processed.
For example: (FIXME! XREF to detail data ?)
d 878 No such local user: 'bond'.
It should be noted, that in sender and recipient fields the first two field values (channel and host) cannot contain embedded spaces, but the third field value (the address) may. Therefore, in the presence of extra fields, parsing within Transport Agents must be cautious and not assume that an address does not contain spaces.
As mentioned, the second byte of most fields are used for concurrency control and status indication. This tag byte can contain several values that indicate current or previous activity. The fields where this is relevant are the destination (recipient) address and diagnostic fields. The tag values are defined in the “mail.h” file mentioned previously, as follows:
#define _CFTAG_NORMAL ' ' /* what the router sets it to be */ #define _CFTAG_LOCK '~' /* that line is being processed, lock it */ #define _CFTAG_OK '+' /* positive outcome of processing */ #define _CFTAG_NOTOK '-' /* something went wrong */ #define _CFTAG_DEFER _CFTAG_NORMAL /* try again later */ |
The extract above is self-explanatory.
A message control file will normally contain a preamble that specifies information about the associated message file, the message body offset, an error return address, and a log entry tag. After this comes a repeated sequence of: sender address field, recipient address fields, and the message header corresponding to these recipients. After as many of these groups as are necessary, any diagnostic fields will be appended to the end of the control file. The restrictions on the sequence of addresses and message headers, are that a sender address field must precede any recipient address field, and a recipient address field must (immediately) precede any message header field, and no sender or recipient addresses may follow the last message header field.
E.4. Database File Formats
E.4.1. The dbases.conf file
Sample of $MAILVAR/db/dbases.conf file:
#|
#| This configuration file is used to translate a semi-vague idea
#| about what database sources (in what forms) are mapped together
#| under which lookup names, and what format they are, etc..
#|
#| This is used by 'zmailer newdb' command to generate all databases
#| described here, and to produce relevant .zmsh scripts for the
#| router to use things. The 'zmailer newdb' invocation does not mandate
#| router restart in case the database definitions have not changed
#| (reverse is true: If definitions are added/modified/removed, the router
#| MUST be restarted)
#|
#|Fields:
#| relation-name
#| dbtype(,subtype)
#| dbpriv control data (or "-")
#| newdb_compile_options (-a for aliases!)
#| dbfile (or "-")
#| dbflags (or "-") ... (until end of line)
#|
#| The dbtype can be "magic" '$DBTYPE', or any other valid database
#| type for the Router. Somewhat magic treatment (newdb runs) are
#| done when the dbtype is any of: *DBTYPE/dbm/gdbm/ndbm/btree
#|
#| The "dbfile" need not be located underneath of $MAILVAR, as long as
#| it is in system local filesystem (for performance reasons.) E.g.
#| one can place one of e.g. aliases files to some persons directory.
#|
#| At dbflags (until end of the line), characters ':' and '%' have special
#| meaning as their existence generates lookup routines which pass user's
#| optional parameters. See documentation about 'dblookup'.
#|
#|Example:
#|
#|Security sensitive ones ("dbpriv" must be defined!)
#| aliases $DBTYPE 0:0:644 -la $MAILVAR/db/aliases -lm
#| aliases $DBTYPE root:0:644 -la $MAILVAR/db/aliases-2 -lm
#| fqdnaliases $DBTYPE root:0:644 -la $MAILVAR/db/fqdnaliases -lm
#| userdb $DBTYPE root:0:644 -la $MAILVAR/db/userdb -lm
#|
#|Security insensitive ones ("dbpriv" need not be defined!)
#| fqdnaliasesldap ldap - - $MAILVAR/db/fqdnalias.ldap -lm -e 2000 -s 9000
#| fullnamemap $DBTYPE - -l $MAILVAR/db/fullnames -lm
#| mboxmap $DBTYPE - -l $MAILSHARE/db/mboxmap -lm
#| expired $DBTYPE - -l $MAILVAR/db/expiredaccts -lm
#| iproutesdb $DBTYPE - -l $MAILVAR/db/iproutes -lmd longestmatch
#| routesdb $DBTYPE - -l $MAILVAR/db/routes -lm%:d pathalias
#| thishost $DBTYPE - -l $MAILVAR/db/localnames -lm%d pathalias
#| thishost unordered - - $MAILVAR/db/localnames -ld pathalias
#| thishost bind,mxlocal - - - -ld pathalias
#| otherservers unordered - - $MAILVAR/db/otherservers -lmd pathalias
#| newsgroup $DBTYPE - -l $MAILVAR/db/active -lm
aliases $DBTYPE 0:0:644 -la $MAILVAR/db/aliases -lm
fqdnaliases $DBTYPE root:0:644 -la $MAILVAR/db/fqdnaliases -lm%
userdb $DBTYPE root:0:644 -la $MAILVAR/db/userdb -lm
routesdb $DBTYPE - -l $MAILVAR/db/routes -lm%:d pathalias
thishost $DBTYPE - -l $MAILVAR/db/localnames -lm%d pathalias
#| =================================================================
#| Set of boilerplate tail-keepers, these lookups fail ALWAYS.
#| These are given because if user ever removes any of the relations
#| mentioned above, the generated "RELATIONNAME.zmsh" script won't
#| just magically disappear!
#| =================================================================
aliases NONE - - - -
expired NONE - - - -
fqdnaliasesldap NONE - - - -
fqdnaliases NONE - - - -
fullnamemap NONE - - - -
iproutesdb NONE - - - -
newsgroup NONE - - - -
otherservers NONE - - - -
routesdb NONE - - - -
thishost NONE - - - -
userdb NONE - - - -
#| NOTE: mboxmap MUST NOT exist at all if its secondary-effects
#| are to be avoided!
|
E.4.2. Aliases File
For relation: aliases
Syntax of this file is simple: blank lines, and comments with “#” character at column 1 are ignored, the key is non-white-space string of characters terminating on double-colon + whitespace (actually '"quoted string":' is also valid key!), rest of the line (and possible continuation lines) are data.
postmaster: root postoffice: root MAILER-DAEMON: root mailer: postmaster postmast: postmaster proto: postmaster sync: postmaster sys: postmaster daemon: postmaster bin: postmaster uucp: postmaster ingress: postmaster audit: postmaster autoanswer: "|@MAILBIN@/autoanswer.pl" nobody: /dev/null no-one: /dev/null "no body": /dev/null junk-trap: /dev/null #test-gw: "|/..." #test.gw: "|/..." |
Doing expansion lists in sendmail(8) style is not suggested, although we certainly
can do it. There is a better mechanism in the ZMailer to handle simple feats like these that sendmail(8) systems do by placing the file containing recipient addresses into the directory $MAILVAR/lists/. This directory must have protection of 2775 or
stricter, and the listfile must have protection of 664 or stricter for *-request/owner-*/*-owner auto-aliases to work.
— but to sendmail style lists:
listname: "/usr/lib/sendmail -fowner-listname listname-dist" owner-listname: root # Well, what would you suggest for a sample ? listname-owner: owner-listname listname-request: root listname-dist: ":include:/dev/null" |
E.4.3. FQDNAliases File
This is syntactically alike the aliases database (the double-colon + whitespace terminate the key), rest of the line (and possible continuation lines) are data, however it can have some interesting keys:
- local@domain:
-
Matches given address, including possible incoming local+tag@domain versions.
- @domain:
-
This matches all addresses with given domain.
The result data may contain “%1” which is filled with user part of the input address, example:
It can thus be used to map e.g. user@domain1 to user@domain2.@domain: %1@domain2
E.4.4. Routes File
For relation: routesdb
Sampling here the default boilerplate “$MAILVAR/db/routes” file:
# Routing Configuration File
#
# Entries in this file are checked first by router.cf.
# They have the form:
# name channel!next_destination
# A leading . on the name indicates that all subdomains match as well
#
# We have TWO different fallback lookup tags:
# .:ERROR for cases where ERROR MESSAGES we generated are being routed
# . for general case
#
# This dictomy is due to need to route everything by explicite tables,
# EXCEPT in case of errors when '.' maps to 'error!something'
# ("We know to whom we route, others get error report back.")
#
# To generate runtime BINARY database of this source, issue command:
# $MAILBIN/newdb $MAILSHARE/db/routes
# or in this directory with usual configuration:
# ../bin/newdb routes
#
#
# Sample route statements (and channels):
#
# .foo error!cannedmsgfilename
# # Canned error message from $MAILSHARE/forms/cannedmsgfilename
#
# .bar smtpx!
# # Send all traffic destined to any subdomain under this
# # suffix via "smtpx" channel to that domain
#
# .bar smtp-etrn!
# .bar smtp-tls!
# .bar smtp-log!
# .bar smtp77!
# .bar smtp77x!
# .bar smtp8!
# .bar smtp8x!
# # Ditto
#
# .bar smtpgw-xyz!
# # Drives genericish gateway function kit
#
# junkdom bitbucket!
# myself local!
# news.domain usenet!
# uunode.dom uucp!uunode
#
# # Usual ISP smart-host setup
# . smtpx!ISP.smtp.gw
#
# # Not so usual - fallback to error, except for error messages
# .:ERROR smtp!
# . error!notourcustomer
#
|
E.4.8. Fullnames
For relation: fullnamemap
This used to be a firstname.lastname keyed mapping database yielding login-ids, but these days this is superceded by ability to have dots in alias keys.
Example:
firstname.lastname loginid |
E.4.14. Mailbox File
Err... Uh.. What can be said ? The standard UNIX mailbox ?
FIXME! Or was this supposed to be the MBOXMAP thing ?
E.5. Scheduler Statistics Log
The statistics log reports condenced performance oriented information in following format:
| timestamp | fileid | dt1 | dt2 | state | $channel/$host |
|---|---|---|---|---|---|
| 812876190 | 90401-2 | 0 | 5 | ok | usenet/- |
| 812876228 | 90401-1 | 0 | 7 | ok | usenet/- |
| 812876244 | 90401-1 | 0 | 1 | ok | local/gopher-admin |
| 812876244 | 90401-1 | 0 | 5 | ok | smtp/funet.fi |
| 812876559 | 90401-1 | 0 | 21 | ok | smtp/utu.fi |
Where the fields are:
timestamp-
The original spoolfile ctime (creation time) stamp in decimal.
fileid-
Spoolfile name after the router has processed it.
dt1-
The time difference from spoolfile ctime to scheduler control file creation by the router.
dt2-
The time difference from scheduler file ctime to the delivery that is logged on.
state-
What happened? Values: ok, ok2, ok3, error, error2, expiry
$channel/$host-
Where/how it was processed.
E.6. Syslogged Log Formats
At syslog facility the system logs also material, if it has so been configured.
Different subsystems do different logs, they are described below.
E.6.1. Smtpserver's Syslog Format
The smtpserver may log in multiple formats:
- INFO: connection from ..., WARN: refusing connection from ..., INFO: accepted id ... into freeze.., INFO: TASPID accepted from...
-
where TASPID: A spool-id that is valid throughout message lifetime in the system, and should be long-term unique, even. (Per system.)
- EMERG: smtpserver policy database problem..., ERR: MAILBIN unspecified in zmailer.conf
E.6.2. Router's Syslog Format
The router does syslog() in following format:
taspid: from=<addr>, rrelay=smtprelay, size=nnn, nrcpts=nnn, msgid=str, delay=xx, xdelay=xx |
Where:
taspid-
The TA-SPOOL-ID — A spool-id that is valid throughout message lifetime
from=-
the envelope source address
rrelay=-
the message “rcvdfrom” envelope header reports.
size=-
Total message size in bytes (envelope+headers+body)
nrcpts=-
Number of recipients for this message
msgid=-
The “Message-ID:” header content
delay=-
Delay from message arrival to the system to this logging moment
xdelay=-
Delay during processing — tells how much time was spent to process the message.
E.6.3. Transport Agent's Syslog Format
The transport agents log in following format:
taspid: to=<addr>, delay=dd, xdelay=xx, mailer=mm, relay=rr (wtt), stat=%s msg |
Here the fields are:
taspid-
The ta-spool-id — A spool-id that is valid throughout message lifetime
to=-
Destination address in whatever form the transport agent uses.
delay=-
Delay from message arrival to the system to this logging moment
xdelay=-
Delay during this processing attempt — tells how much time this time was spent to process the message.
mailer=-
Tells what “channel” was used.
relay=-
Reports on which host the message is relayed thru (“wtthost”), and for SMTP, also (in parenthesis) what was the relay's IP address.
stat=-
What status was achieved: ok*, delayed, failed, ... CHECK!
- msg
-
Arbitrary text line from whatever system is out there.